
- 기본형(primitive) 타입 종류와 값의 범위, 기본 값
- 기본형(primitive) 타입과 참조형(reference) 타입
- 리터럴(literal)
- 변수 선언 및 초기화하는 방법
- 변수의 스코프와 라이프 타임
- 타입 변환, 캐스팅 그리고 타입 프로모션
- 1차, 2차 배열 선언하기
- 타입 추론, var
기본형(primitive) 타입 종류와 값의 범위, 기본값
기본형 타입을 일반적으로 자료형이라고 표현하는데, 자료형을 알기 전 데이터 단위부터 정리하자.

데이터의 가장 작은 단위는 비트(bit, binary digit) 이다. 비트는 0과 1만을 표현한다. 비트가 8개면 바이트(1byte = 8 bits) 가 되며, 표현할 수 있는 수는 28이 된다.
비트와 바이트외에도 워드(word)라는 단위가 존재한다. 워드는 CPU가 한 번에 처리하는 데이터의 크기 를 의미한다고 한다. 워드는 CPU에 따라 단위가 달라지는 특성이 있는데, 32비트 CPU에서는 1워드는 4 바이트(32 bits)이고, 64비트 CPU에서 1워드는 8 바이트(64 bits)가 된다.
출처 : 남궁성 - Java의 정석
| 분류 | 타입 | 크기 | 값 범위 | 설명 |
|---|---|---|---|---|
| 논리형 | boolean | 1 byte | false, true | true, false만을 표현하기 때문에 자료형중 가장 작은 크기를 가진다. |
| 문자형 | char | 2 bytes | '\u0000' ~ '\uffff' | 문자를 저장하는데 사용되며, 하나의 문자만 변수(variable)에 저장이 가능하다. 자바에서 유니코드를 사용하므로 하나의 문자는 2 byte(8 bits)가 된다. |
| 정수형 | byte | 1 byte | -27 ~ 27-1 | 정수를 저장하는데 사용되며 주로 int가 사용된다. 이진데이터를 다루기 위해 byte를 사용하며, C언와의 호환을 위해 short이 추가되었다. int(4 bytes)를 기준으로 int보다 작은 short(2 bytes), int보다 긴 long(64 bytes)으로 기억하면 좋다. |
| short | 2 bytes | -215 ~ 215-1 | ||
| int | 4 bytes | -231 ~ 231-1 | ||
| long | 8 bytes | -263 ~ 263-1 | ||
| 실수형 | float | 4 bytes | 1.4x10-45~3.4x1038 | 실수를 저장하는데 사용되며, float(4 bytes)보다 2배의 크기(8 bytes)를 갖는 double을 실수형 자료형으로 주로 사용한다. |
| double | 8 bytes | 4.9x10-324~1.8x10308 |
출처
실제 기본형 타입의 크기를 인텔리제이 디버거를 통해 확인해보았다.

타입 메모리 크기를 알아야 하는 이유
타입의 메모리 크기를 알아둬야 하는 이유가 있다. 자료형 크기와 맞지않는 리터럴을 대입하려고 하면 아래와 같은 케이스가 발생할 수 있다.
- 언더플로우
- 자료형 크기보다 작은 리터럴을 표현하려고 할 때 발생.
- 에러는 아니지만, 메모리 누수가 발생함.
- 오버플로우
- 자료형 크기보다 큰 리터럴을 대입하려고 할 때 발생
- 컴파일러가 데이터를 표현할 수 없어서 컴파일 에러 발생
아래의 예제코드를 보자.
1 | public class PrimitiveType { |
두 정수의 평균값을 구하는 코드이다. 결과는 어떨까?
1 | -3 |
예상한 평균값과 다른 값이 나왔다. 왜 그럴까?
int형으로 표현할 수 있는 최대 크기의 정수가 2_147_483_646인데, num1과 num2를 더하면서 이미 int형의 표현범위를 벗어났기 때문이다.
따라서 위의 코드를 원하는 결과로 출력하려면 아래처럼 하면 된다.
1 | int mid2 = num1+(num2-num1)/2; |
두 수중 더 큰 수에서 작은 수를 빼서 나오는 만큼의 마진과 작은수를 더하면 int형의 표현범위 내에서 연산이 발생하므로 원하는 값이 출력된다.
1 | public class PrimitiveType { |
1 | -3 |
기본형(primitive) 타입과 참조형(reference) 타입
- 기본형 타입 : 실제 값 을 가지는 타입
- 참조형 타입 : 실제 값을 갖는 주소 를 가리키는 타입
기본형 타입은 위에서 정리를 했다. 기본적으로 논리형, 문자형, 정수형, 실수형 4가지로 분류되는 8가지 자료형을 기본형 타입이라 하며, 그외 이런 기본형 타입을 참조하는 타입을 참조형 타입이라 한다.
기본형 타입과 달리 참조형 타입은 클래스의 이름을 변수의 타입으로 사용하기 때문에 클래스가 곧 참조변수의 타입이 된다. 따라서 새로운 클래스를 생성한다는 것은 새로운 참조형을 추가한다고 볼 수 있다.
참조형 타입 String에서의 값 변경
문자열은 기본형타입이 아닌 참조형 타입이다.
기본형 타입의 데이터는 런타임 스택에 저장이 되서 관리된다. 참조형 타입의 데이터는 런타임 스택에 값이 아닌 값의 주소를 저장한다. 이 주소가 가리키는 실제 값은 힙 영역에 할당된다.
따라서 참조형 타입인 String은 따라서 불가변한 객체라 할 수 있다. String이 왜 불가변한 객체인지 아래를 따라가보자.
1 | String name = "Andy"; |
위의 코드에서 문자열 변수 name은 값이 변경한게 아니라 가리키는 주소가 변경되었을뿐이다.
1 | String name = new String("Andy"); |
본래 참조형 타입은 new 키워드로 생성해야 하나 String은 JVM의 Heap 영역에 존재하는 String Constant Pool 덕분에 문자열 변수는 new 키워드 없이도 객체를 선언할 수 있다.
또 new 키워드로 객체를 생성하면, Heap에 새로운 객체가 생성되는데, String 변수를 직접 선언하면, String Constant Pool에 있는 주소값을 공유하면서 참조하기 때문에 참조하려는 주소가 String Constant Pool에 존재할 경우 Heap에 새로 생성하지 않고 주소값을 공유하여 참조할 수 있다.
이 때문에 문자열 변수는 new 키워드없이 사용하는게 String Constant Pool을 사용할 수 있어서 메모리 관리에 더 효율적이다. 아래 예제 코드를 보자.
1 | String seoulAir = "Clean air"; |
위의 코드에서 3개의 변수는 모두 같은 문자열 리터럴을 할당받고 있지만, seoulAir와 tokyoAir은 서로 같은 주소를 참조하고, china Air는 다른 주소를 갖게 된다.
비교연산자를 통해 비교해보면 확인이 된다. 그리고 실제 주소값을 출력해보면 아래와 같다.
1 | public class JavaBasic { |
1 | true |
seoulAir와 tokyoAir의 주소는 서로 같은 주소를 갖고있는걸 알 수 있다. 따라서 String은 참조형 타입이지만 new 키워드로 객체를 생성하는 대신 리터럴을 직접 대입하는것처럼 생성해야 메모리를 효율적으로 관리할 수 있을것으로 판단된다.

출처 :
리터럴(literal)
값을 저장하는 타입으로 변수(variable)와 상수(constant)가 존재한다. 변수는 가변성을 지니지만, 상수는 변수와 달리 불가변하다는 특징이 존재한다.

위의 코드를 보면, num1은 값의 변경이 가능하지만, final 키워드가 붙어서 상수로 선언된 NUM2는 연산이 되지않아 인텔리제이에서 에러를 발생시키는걸 알 수 있다.
참고로 상수는 final 키워드와 함께 상수명을 대문자로 작성한다는 특징이 있다. 소문자로 작성해도 컴파일에 문제는 없지만, 상수는 대문자로 표현하는것이 약속과 같다.

변수와 상수에 들어가는 값, 이 값을 리터럴 이라고 한다.
위의 코드에서 num1 은 변수로, num2 는 상수로 선언되었는데 여기에 대입된 각각의 값 30, 1991이 리터럴에 해당한다.
리터럴에도 자료형에 따라 타입이 존재한다.
| 종류 | 리터럴 | 접미사 |
|---|---|---|
| 논리형 | false, true | 없음 |
| 정수형 | 123, 0b0101, 0xFF, 100L | int형 리터럴에는 접미사가 없지만,Long형 리터럴에는 접미사 L을 붙힌다. |
| 실수형 | 3.14m 3.0e8, 1.4f | float형의 리터럴에는 f,double형의 리터럴에는 d를 붙힌다. |
| 문자형 | 'A', '1', '\n' | 없음 |
| 문자열 | "ABC", "123", "A" | 없음 |
출처 : 남궁성 - Java의 정석
접미사는 정수형, 실수형 자료형에만 필요한걸 알 수 있다. 위의 테이블을 요약하면, 정수형 실수형만 리터럴에 접미사가 요구되며, 접미사가 없으면 int형으로 인식하며, 접미사가 있을경우 해당 접미사에 따라 리터럴의 타입으로 인식된다.
1 | // 정수형 리터럴 |
리터럴을 사용할 때 유의할 것들이 몇 가지가 있다.
리터럴과 변수의 자료형 타입이 일치하지 않으면 컴파일 에러가 발생한다.
1 | byte num = 100_000; // 리터럴의 byte의 표현 범위를 벗어나므로 컴파일시 에러를 유발한다. |
문자형과 문자열의 차이
문자형(char)과 문자열(String)은 리터럴을 감싸는 표기를 어떻게 하느냐에 따라도 인식이 달라질 수 있다. 참고로 문자형(char)은 기본형 타입(primitive)에 해당하는 타입이지만, 문자열은 참조형 타입(String.class) 에 속한다. (위 자료형 테이블 참고)
| 리터럴 타입 | 기호 |
|---|---|
| 문자형(char) | '' |
| 문자열(Strnig) | "" |

인텔리제이에서 따옴표만 다르게해서 변수를 선언하고 대입해보았지만, 쌍따옴표로 리터럴을 감싸니 리터럴을 문자형이 아닌 문자열로 인식을 하는걸 알 수 있다.
문자형(char)과 문자열(String)의 또 다른 차이중 하나는 null을 대입할 수 있느냐 없느냐의 차이가 있다. 문자열 변수엔 null을 대입할 수 있지만, 문자형 변수엔 null 대입이 불가능하다.

뿐만 아니라 빈 값 을 대입하는 방법도 마찬가지다. 문자열(String)은 빈 값이 대입할 수 있지만, 문자형(char)은 빈 값을 대입할 수 없다.

변수 선언 및 초기화하는 방법
자바에서 변수를 선언하는 방법은 아래와 같다.
1 | int num = 12; |
자료형을 먼저쓰고, 변수명을 쓰면 변수를 선언할 수 있다. 그리고 변수 선언과 동시에 값을 대입하면, 이 값이 변수의 초기값이 된다.
초기값의 경우 기본값(default value) 이라는게 존재한다. 변수 선언할 때 개발자가 따로 대입하지 않아도 변수로 선언되는 동시에 갖는 기본값이다.
| 자료형 | 기본값 |
|---|---|
| boolean | false |
| char | ‘\u0000’ |
| byte, short, int | 0 |
| long | 0 |
| float | 0.0f |
| double | 0.0d or 0.0 |
기본형 타입(primive)외에 참조형 타입(reference)은 객체이므로 null을 기본값 으로 갖는다.
기본값이 이렇게 있음에도 초기화를 해야하는 이유가 뭘까?
1 | public class StudyHale { |
위의 StudyHale 클래스는 타입이 각각 다른 4개의 변수를 각각 클래스와 메인 메서드안에 초기화하지 않고 선언한 클래스이다. 클래스에 선언한 변수는 인스턴스 변수, 메ㅓ드 내부에 선언한 변수는 로컬 변수라한다.
초기화하지 않고 선언했을때, 각각 기본값이 어떻게 적용하기 위해 컴파일하면 어떤 일이 발생할까?

인스턴스 변수들까지는 문제가 없고, 로컬 변수들이 문제였다. 인텔리제이 경고창을 통해 변수들이 초기화해야한다고 경고를 하고 있다.
같은 이름의 변수임에도 불구하고, 스코프(scope) 에 따라 기본값 적용여부가 달라자는 것이다. 변수의 스코프가 클래스 일 때에만 기본값이 대입되고, 메서드 안에서 선언된 변수의 경우 기본값이 적용되지 않기 때문에 반드시 초기화 해주어야 한다.
변수의 스코프와 라이프 타임
위에서 스코프라는 단어를 사용했는데, 스코프란, 변수를 사용가능한 범위 를 표현한다.
1 | public class StudyHale { |
위의 클래스에서 변수 num은 같은 이름으로 3번 선언되었는데, 모두 선언된 위치가 다르다. 하나는 클래스 내부이면서 메서드 외부에, 다른 하나는 main()에, 나머지 하나는 printNum()에 선언되었다.
메인 메서드를 실행하면, 다음과 같은 결과를 출력한다.
1 | 12 |
main() 에서 출력한 num은 main() 내부에서 선언한 변수를 출력했고, printNum()을 통해 출력된 num 은 printNum() 내부에서 선언된 num을 출력한 것이다.
변수를 사용할땐 이처럼 이름이 같더라도 스코프에 따라 구별됨을 알 수 있다.
스코프에 따른 변수는 크게 3가지로 분류된다.
인스턴스 변수(Instance Variable)

정의
인스턴스 변수는 클래스 내부에 선언되었으면서 메서드 외부에 선언된 변수를 정의한다.
스코프
static 메서드를 제외한 클래스 어디서나 접근 가능하다.
라이프 타임
라이프 타임이란, 객체가 생성되어 GC에 의해 제거될때까지 를 의미한다.
인스턴스 변수의 라이프 타임은 인스턴스 객체가 생성되는 시점부터 객체의 사용이 다해서 GC에 의해 제거될 때까지이다.
클래스 변수 (Class Variable)

정의
인스턴스 변수처럼 클래스 내부와 메서드 외부에 선언된 변수이지만, static 키워드가 붙는다는 점에서 다르다.
스코프
클래스 어디서나 접근가능하다. (static 메서드에서 접근불가능한 인스턴스 변수보다 스코프가 넓다.)
라이프 타임
클래스가 호출되는 시점에 메모리에 할당된다. 클래스가 호출되는 시점이란, 말그대로 해당 클래스가 호출되는 시점에 클래스 변수가 메모리에 올라간다.
클래스 변수의 생성시점과 인스턴스 변수와의 차이에 대해 다음 포스팅(클래스변수와 인스턴스 변수 차이(생성시점))에서 정리해두었다.
출처
로컬 변수(Local Variable)

정의
메서드 내에서 선언된 변수이다.
스코프
메서드 내부에서만 사용할 수 있다.
라이프 타임
로컬 변수가 선언된 메서드가 호출될 때 메모리에 할당되어 메서드가 사용을 마치면, GC에 의해 제거된다.
출처
타입 변환, 캐스팅 그리고 타입 프로모션
타입 변환과 타입 캐스팅을 동일한 개념으로 오해하고 있었는데, 이번 라이브 스터디를 하며 제대로 알게 된 개념들이다.
타입 변환
타입 변환이란, 리터럴의 데이터 타입을 다른 데이터 타입으로 변환하는걸 의미한다. 예를들면 다음과 같은 코드가 타입 변환에 해당한다.
1 | char ch = 'A'; |
char형 변수 ch를 int 형으로 타입을 변환했다. char형을 int형으로 형변환하면 아스키코드값으로 변환된다.
여기까지는 뭐 단어의 의미만으로 다 알수있는 내용이다. 이 타입 변환은 자료형의 표현범위에 따라, 변수의 메모리 크기에 따라 타입 캐스팅과 타입 프로모션으로 구분될 수 있다.
- 타입 프로모션
- 크기가 더 큰 자료형으로 리터럴을 대입할 때 자동으로 타입이 변환되는 것.
- 타입 캐스팅
- 크기가 더 작은 자료형으로 리터럴을 명시하여 강제로 타입 변환 하는 것.
타입 프로모션

리터럴을 더 메모리 크기가 큰 자료형에 대입하는 경우를 프로모션이라고 한다. 개발자가 명시적으로 타입 변환하지 않아도, 자동으로 타입이 변환된다.
그러나 인텔리 제이에서 보는것처럼 해당 자료형이 필요보다 크다는 alert를 띄워준다. 메모리 누수를 걱정하는 alert이다.
타입 캐스팅
위에서 정리했던 자료형 테이블을 보면, char형이 16 bits, int형이 32 bits의 표현 범위를 갖기 때문에 char형 리터럴은 개발자가 명시하지 않아도 int형으로 프로모션될 수 있다.
1 | char ch = 'A'; |
그럼 반대로 하면 어떨까?

자동 타입 변환이 이뤄지지 않는다.
원래의 자료형보다 더 표현 범위가 작은 자료형으로 타입 변환을 시도하기 때문에 자동 타입 변환이 되지 않는 것이다.
이 때 개발자가 변환할 타입을 리터럴에 명시함으로써 강제로 타입을 변환하는 것을 타입 캐스팅이라고 한다.
1 | int num = 65; |
65의 아스키 코드값 A로 값이 타입 캐스팅된 것을 확인할 수 있다.
1차, 2차 배열 선언하기
배열은 복수의 리터럴을 저장할 수 있는 객체이다. 배열의 리터럴로 기본 자료형이 들어오든, 참조형 자료형이 들어오든 배열 자체가 객체이다. 따라서 new 키워드를 사용하여 배열을 선언한다.
1 | String[] arr = new String[10]; |
배열을 선언시 크기를 지정해야 하는 특징때문에 배열의 크기를 변경할 수 없다는 특징이 있다.
1차원 배열은 다음과 같이 선언한다.
1 | public class StudyHale { |
배열은 크기가 고정되기 때문에 new 키워드로 크기만 지정해서 바로 선언할 수 있다.
또는 배열 안에 들어갈 요소(element)를 {}에 담아서 선언할 수 있다. 이 때 요소의 갯수가 곧 배열의 크기에 해당해서 이 크기로 먼저 메모리에 배열의 크기만큼 할당하고, 요소를 하나씩 할당한다.
2차원 배열 선언은 다음과 같다.
1 | public class StudyHale { |
1차원 배열과 마찬가지로 두가지 방법으로 선언할 수 있다.
1차원 배열과 다른 특징이 있다면, 1차원 배열은 .length를 통해 배열의 길이를 반환받을 수 있지만, 2차원 배열부터는 행과 열의 길이를 각각 구해야 한다.
.length는 배열의 행 길이만 반환해준다. 열의 길이를 반환하기 위해서는 for문을 사용하여 행마다 열의 길이를 반환해주어야 한다.
1 | int[][] arr = new int[2][1]; |
1 | 1 |
또 1차원 배열과 다른 점은 1차원 배열은 Arrays.toString()으로 배열을 문자열로 출력할 수 있었다면, 2차원 배열은 for문을 결합해서 출력해야 한다는 특징이있다.
1 | int[][] arr = new int [2][2]; |
1 | [0, 0] |
스터디 과제를 준비하며 다른 사람이 제출한 과제를 통해 알게된 것이 있다. 배열이 메모리에 어떻게 할당하는지를 보여주는 그림이다.
1차원 배열은 다음과 같이 할당된다.
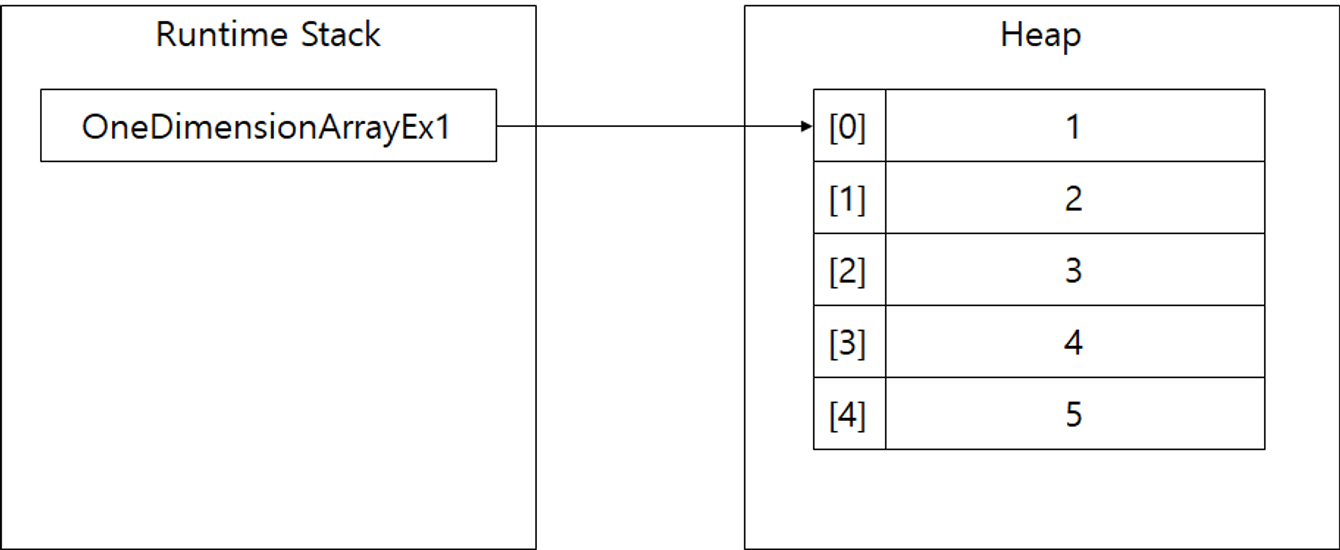
메모리 영역의 스택에 배열이 호출되면, 배열의 각 요소는 배열의 크기만큼 할당된 Heap 영역의 주소를 가리킨다.
2차원 배열은 다음과 같이 할당된다.
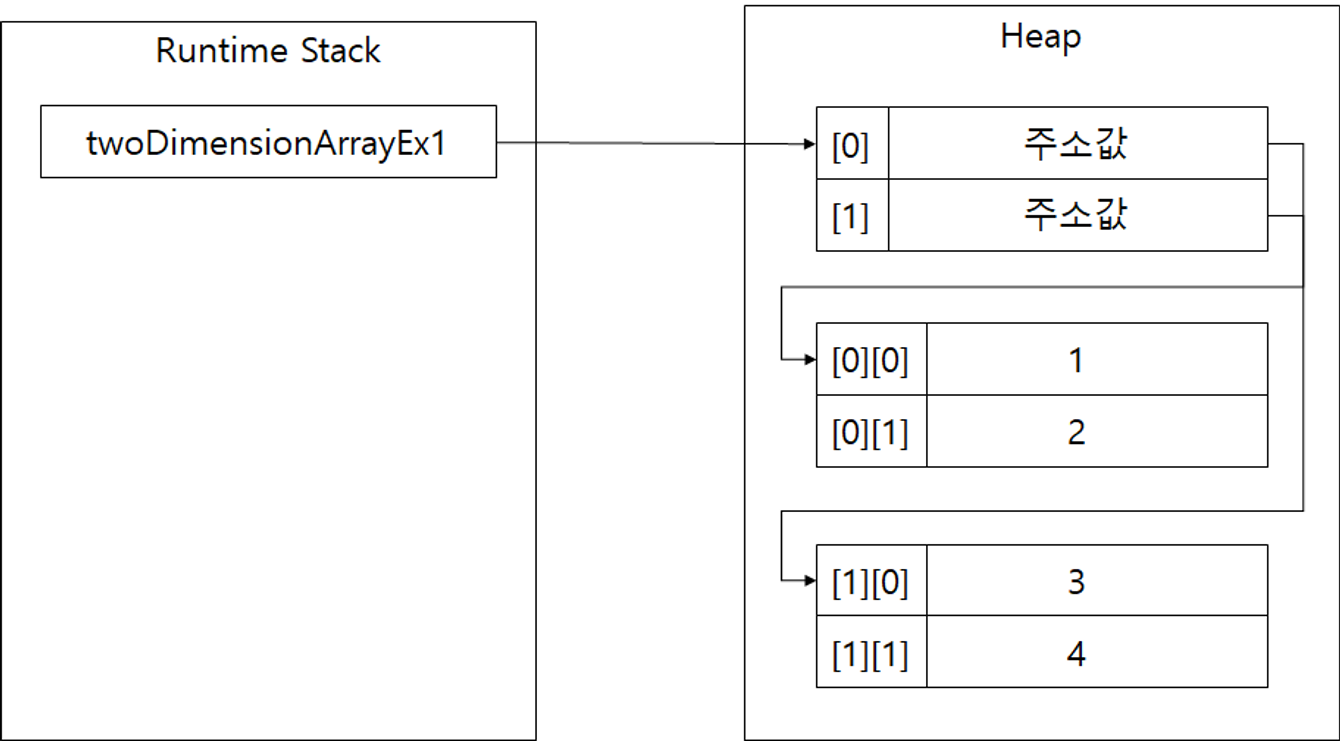
2차원 배열은 배열의 배열로 선언하기 때문이다.
1 | int[][] arr = new int[2][2]; |
위의 2차원 배열 arr은 아래와 같이 선언할수도 있다.
1 | int[ ][] arr = new int[2][]; |
2차원 배열부터는 배열의 배열이기 때문이다.
각각의 행에 new 키워드를 사용하여 배열을 선언할 경우 행마다 다른 길이의 열을 갖는 배열을 선언할수 있는데, 이를 가변 배열 이라 한다.
1 | int[ ][] arr = new int[3][]; |
1 | 0 0 0 |
출처 - damho1104님 Notion
타입 추론, var
타입 추론이란, 말그대로 변수의 타입을 추론하는 것인데 개발자가 직접 추론하는게 아니라 바이트코드로 컴파일 하는 단계에서 컴파일러가 타입을 추론하는걸 의미한다.
아래의 예제 코드를 보자.
객체의 클래스 이름을 가져오는 함수로 getClass().getSimpleName() 을 사용했다.
StudyHaleEx01 클래스의 메인 메서드를 실행하면 다음과 같이 출력된다.
1 | String |
콘솔에 출력한 변수는 모두 var 로 타입추론한 변수들이다. 즉 개발자가 컴파일러에게 객체의 타입을 명시하지 않았음에도 컴파일러가 타입을 추론한걸 확인할 수 있다.
이 타입 추론은 기본 자료형에는 적용되지 않는다. 오직 객체의 타입 추론에만 사용가능하다. 따라서 int 형 변수의 타입 추론은 안되지만, Integer 의 타입추론은 가능하다.
